Data in Health

Next: Using Data without Revealing Personal Data
Data
Personalisation is naturally dependent on availability of data. Both inherited and environmental factors affect our wellbeing and create or prevent future health risks. It is easy to forget their impact in daily life as they work on a slow scale – over decades rather than giving immediate feedback. Such factors as sleep, healthy food, intake of alcohol and smoking, exercise, stress, accidents, DNA, what genes in DNA are switched on or off due to life events, microbiota (i.e., microbes inside us,) social relations, employment and line of work, hobbies, cultural habits, personal learned habits, where we live (noise, chemicals around us, micro-particles in air), weather, chronic conditions etc.

Numerous different organisations produce and handle each their own slice of the data.
In today’s medical care only the health care data is used. And health care data is really sickness data. Information about already present, harmful results.
Main sources generating data that is relevant for our health include:
All public and private health care data: visits, lab tests, imaging data, diagnoses, prescriptions, operations, information gathered during hospital stay, vaccinations etc.
Information from domiciliary care (visits, blood sugar, PEF measurements)
Data from insurance companies (insurance claims, attachments and decisions)
Social sector data (unemployment data, mental health data, different benefits, disabilities, pensions etc.)
Voluntary wearables data (exercise like running, swimming walking, amount and quality of sleep, blood pressure, heart rata, weight, height, ECG etc.)
Memberships (in sports associations and other activities)
Information about diet
DNA and history of diseases in family
Construction data from living and working places like materials used in construction etc.
Smart home and office sensor data (noise inside, indoor air quality)
Smart city data (temperature, humidity, air quality (fine particles in air), traffic jams etc.)
Network effects (as you learn habits from friends) – social media networks
Since health data is sensitive, combining all will be impossible, but it is good to understand the factors first. At minimum people should be able opt-in/opt-out and control with details their data are available to who and have visibility who has accessed their data. Aggregation of data is another option where personalised details are no longer present. Aggregation requires to collect the data first.
Much of this data is already widely available without general public being too aware or concerned about it. Let’s look at location data only to see how health and other personal data can be mined indirectly. If the social graph is known (through my phone book for example), the accuracy becomes even better.
Location tells for example work status (travel on weekdays regularly to an office or factory location), where I work (can infer employer with some accuracy), at what time I go to work (indication of type of work I do), how long I spend at work (part time, full time), where I eat my lunch, or how long have I been unemployed. It also tells where I live. This together roughly tells my income level. Or whether I am a child or a student at university. Place of study tells roughly what I study and how long I have been going to the same school with the type of school tells approximately how old I am.
Location also tells if we are having a baby in family (visits to maternity clinic), deaths in family, some hobbies and memberships in associations, exercise habits, how often I eat out or go to bars – i.e., drinking habits, sometimes sexual orientation (based on specialised venues visited), religious beliefs and how firm they are etc. All of this is today given to unknown third parties who have made an app like a calculator or torch asking for location data.
Below is an is an overview of health data and its potential users
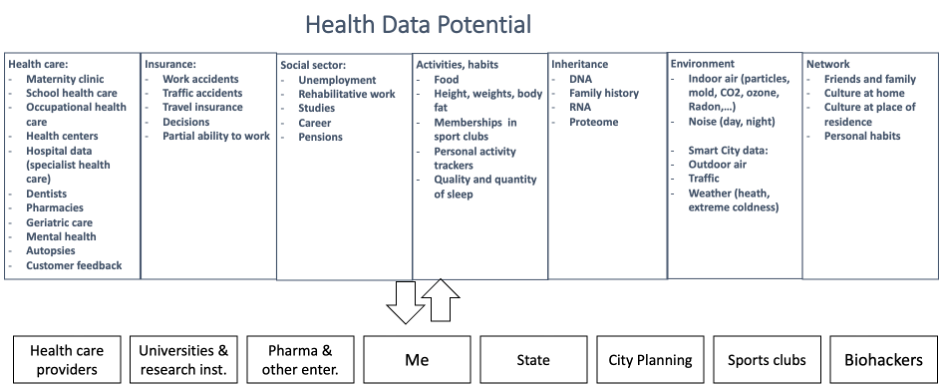
A multitude of users can benefit from such a data store. Biggest naturally are health care providers. Broad data from different aspects gives better insight and allows to finding previously undetected side effects or correlations that prevent effective treatment.
Such data store allows answering a number of interesting questions that currently go unanswered :
Medical care
Outcomes. How effective are different treatments for different types of people? This will lead to personalised medical care that works in real time as discussed in previous post
Consistency. Do people in different parts of the country receive same quality of treatment or are there other factors affecting treatments?
Quality. Do patients need to return back for more treatments - i.e., is there need for more training of personnel, lack of resources, leadership problems in some areas or is there a systemic failure in health system creating excessive amounts of failure demand?
Where are the bottlenecks in health care system and what is their impact for patients - how does queueing time affect the progression of diseases ? Can we calculate a monetary cost for that?
Operation effectiveness tester. The data also tells how much bigger the benefits of operation are than the side effects. Are some operations performed unnecessarily without actual health benefits?
Overmedication tester. A service that looks at your data and finds out if you may be overmedicated. There are risks with such service especially in environments where legal practices favour litigations.
Correlation to environment. Do some chemicals used in buildings or everyday products correlate with presence of some diseases?
Correlation. What’s the effect of noise to sleep and its true cost?
Correlation. How does unemployment affect health? How effective are current methods like sending unemployed to courses – what works and what not?
Rehabilitation
How do different post-operation workout practices affect recovery?
What’s the right balance between exercise and rest?
How do different training practices work for different people?
How to best motivate people – as example different gamification techniques?
Pharma industries
Efficacy of medicine with different types of people. What parameters have an impact of increasing or decreasing impact?
Wearable manufacturers. Improve how various campaigns that motivate people for healthier living work.
Enterprises
Construction companies. How do various building materials and construction choices/architectural decisions affect factors like noise, air quality and what impact this has to peoples’ health. What about own employees, how are they affected by work environment and what aspect there has biggest impact?
How do different chemicals used like plasticisers work on population level (i.e., is there an effect)?
City planning
How do different designs for city affect peoples’ health? What is the effect of noise, air quality? How do different city plans affect price levels of property? Quantify the cost of poor designs in term of money lost.
How do green areas in particular work as filtering pollutants and how does it affect peoples’ mood, property values?
Do some parts of the city cause stress for people and why? Where are pollution and noise levels too high?
Sports
How do different post-workout practices and supplements affect recovery?
How do different training practices work for different people?
Can we predict over-exercise and when risk of injury increases?
How to best motivate young athletes?
Is someone overexercising so that it hurts their health?
Biohackers
How to improve my performance in different areas of life? How does my body respond to different choices in food, sleep, exercise etc.?
Individual
Real time view of what information different parties have of me
Managing who can use my information and for what purposes
Rate every touch point with service providers so that my views can be taken into account when services are improved. Getting feedback when those views are being implemented.
Getting feedback how my current lifestyle is affecting my future health
In next post we look at how health data can be analysed and what risk lie there.
That’s roughly the story of what is health related data and where it might be of use. In next post we look at how that data can be used in privacy preserving manner.