Using Health Data without Revealing Personal Data

Next: Health Operator
In previous post we looked at what type of data is relevant for health related services and how that drives personalisation of interventions. Let’s take a swipe how that data could be used as personal data is quite different from any other data type.
The core idea is to preserve users identity and still share health data that can be used.
Options: Sandbox, Differential Privacy and FLOC
Health data is highly sensitive. For both personal and public benefits number of different service providers have a valid need to access such data. How should data access be provided?
Data is just bits and once data has been handed over a fence between organisations, no one knows how it gets handled or whether it gets distributed further. National governments can sanction misuse of data but they do not have influence abroad.
Thus, its best to keep data in a secure sandbox environment and allow only data analysis within that environment. It also needs to be anonymised and encrypted when stored on disk should some gain physical access or even if own employees get curious about health of public figures.
There are a number of other things to consider. Even analysis results can be used to breach privacy if returned results are not from a sample that is big enough. Assume a query returns that only one person meets the criteria, there are cases where it is not too difficult for an adversary to find out who this person is using external data. Let’s say that this individual travels regularly via a given rail road station at 8AM and your data shows they are 80 years. You can just go there and see who this person is.
To mend off such threats every query needs to be screened before and after execution to look for “leakage” even when it is run inside the sandbox. For good measure its good to have a permanent bounty program for people who find ways penetrate its protections.
Even when a single query prevents revealing identity, a sequence of queries may do it. Assume three queries with different result sets all using same pseudonyms for users. The intersection of these queries can become quite narrow.
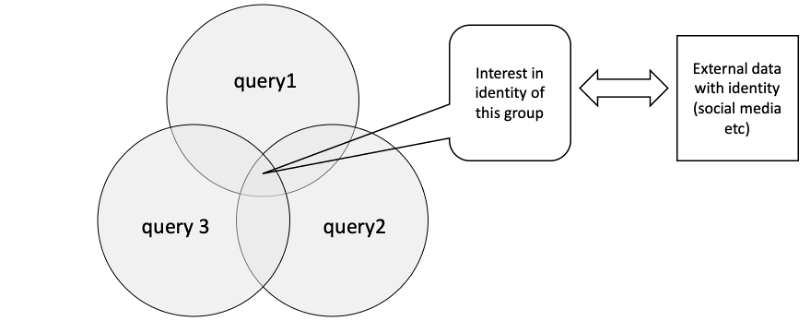
The sandbox thus needs to allocate regularly new pseudo-identities for people, possibly for each query.
The sandbox can limit its result to summary data as another option. For some users it may only allow access to summary results over larger user groups.
Differential privacy
Sandbox is not the only trick possible. Differential privacy is a mathematic approach to increase privacy. The core idea is to add random noise to each data item in a way that maintains the statistical characteristics of data set. I.e., every row is incorrect but the whole data set has correct statistical properties. This enables to learn information about the population without revealing detailed data about any individual.
Decentralised Map-Reduce
There is an alternative to a central sandbox health data storage.
Technically it is possible to make a system where each person holds their own data at their own database at home fr example in some smart device and when a query is made, a central dispatch computer sends the query to all the home nodes to get certain data and the results are then combined in other decentralised nodes before the final result is presented to the researcher.
For those who are technically inclined this would be a modification of the so-called Map-Reduce algorithm used in centralised big data systems. Here just the the data nodes are decentralised all across the nation at users’ locations not in the same data center next to each other. The algorithm will need some changes because a sizeable portion of data may not be accessible at any given time because data link is down or the owner has switched off their devices to conserve energy.
A benefit of this approach is that users get information of every time someone accesses their data. And additional design question is how to protect the data while it is being aggregated at intermediate nodes.
Federated Learning
Federated learning is another option. It is a machine learning technique that trains a predictive algorithm across multiple decentralised devices or servers that have data about their users without sharing that data.
The core idea is that a model is first created centrally and then sent to each end point. Then each device improves that model using their own data and sends the trained models back to the central place and an aggregate model over thousands or millions of users is built. Then this model is shared back to be used as a baseline for training a further improved model.
The good point about this is that data is never shared and everyone gets a personalised model that is likely to work better than a general model that “averages out” data.
A variant of this can be used in a hospital where many patients are present. There a company or organisation can collect data from a large number of patients and build predictive models over that cohort. As a combinatory model the results can no longer be used to learn anything about an individual patient, Then these models can either be directly used for predictions or combined with other models from other health institutes. When learning is done on individual level, the resulting model can potentially be used to learn facts about that person if the security of the central combining function is breached and someone gains access to models and can link them to persons.

Figure. Federated Learning
FLOC is already an existing model.
Browser makers are using it to build advertising models that respect user privacy. Smart speaker makers have used to build personalised language recognition models – that is models that do not only understand spoken language but distinguish between speakers
Some further examples from other verticals below.
Construction companies could instrument buildings and let buildings keep data local and still create predictive models for failures. In factories it can be used to build predictive care models for manufacturing devices. Small-scale web shops could use it to build customer behaviour models. Web forums can use it to build automated filtering systems.
One might think that this changes the need for data market places completely as there is no need to share data. However with machine learning models the question is baked into the model. Models answer hard-coded questions. The power from large data sets comes from the ability to explore them, to gain better understanding and to find new relationships that might be based on some causal reason. Federated learning will bite at data markets but won’t replace them.
FLOC limits what questions can be answered as each model is typically created a specific question. For example predicting what type of disease the symptoms correspond to. The models cannot be used for data discovery, answering completely new types of questions. For privacy aficionados this is naturally a good thing.
Offline data
The list of health data on previous post was an opportunity to press panic button on every data item. When people store their entire data sets at home on personal storage and federated learning is used, the need to share it is removed. It is however much easier for a central organisation to invest to have good security against break in attempts. Having data decentralised could mean easier access for wrong people.
A mitigation for this would be to store data offline. This is normally called cold storage. New data would be pumped in through a one-way channel, maybe even manually carrying it with USB stick through so called “sneaker-net”. Model training would happen on this isolated island with offline computing capability.
There still is need to send back the trained model. It could again be moved from cold storage via a physical USB stick.
This seems so complicated that most people are unlikely to see the trouble. But the model is possible if part of the population is extremely sensitive to privacy. There are quite big national differences in that.
Schrödinger’s Data and Incentivising Sharing
We’ve seen that in medical research large datasets containing relevant health data will be instrumental in developing better treatments and medicines. Combining all this data with real time feed of how medical interventions are working will be like a continuous, nationwide lab trial on effectiveness of all medical work on real-time.
The value of it will be enormous to all medical organisations and the value stems from the data of individuals. Medical data like all big data has the characteristic that data of a single individual has practically zero value but combined it is irreplaceable. It is Schrödinger’s Data as it has no value and enormous value at the same time.
Incentives are needed so that people allow access to their atomised data. Just dividing the value generated equally would generate insignificant compensation.
A new medicine can bring in billions of profits yearly and the patents run for many years. In future data access will be practically mandatory in new efficacious drug development.
When reward per individuals is small, one method would be to gamify the reward. Assume for example that 20-30% of price of new drugs goes to people who shared their data. We can divided this lump sum into large a set of large lots – say hundred thousand to a million (euros, dollars) and raffled every week to one or more winners. The money is big enough to have a transformative change in your life in case of a win and you participate passively by just allowing your data to be used. At the same time you know that this data is used in creating treatments that potentially help you as you get older. Philanthropically oriented people could donate their winnings to a good cause of their liking (perhaps without ever knowing of their win to prevent feelings of remorse). And greedy philanthropists could split the reward (half to me in case of win and half to a good cause).
The value of pharmaceutical industry globally is over thousand billion USD in currently on sale medicines. Off license medicines are produced in large quantities by generic pharma manufacturers and command very low price. So even when compensation naturally would apply only to new medicines one can see the potential value to data owners.
Transparency
Another option to help data sharing is transparency, letting people control access to their data.
Here is one way to achieve it.
At the center is my data where I control who has access to my data and I see all the times who has viewed it. Most likely pseudonym of the health user, but if use is inappropriate, I can report it (health employees also have right for privacy).
My Data Console allows to control access rights and see who is authorised to use my data and for what purpose. Periodically a specialist app may go over all the granted rights and inform me if I have accidentally given too much rights to a certain provider. Privacy conscious people may also want to get a notification every time data is accessed or only provide access to a provider by approving each request. In last scenario you get a dialog for asking permissions and if you do not respond the request is granted or denied automatically based on your preference. (this might have adverse effects if you are unconscious so some thought needs to go into service design).
My Data Log stores details on who has accessed my records and when.
The resulting health data model is as in the diagram below:

That’s a starting point for some ways to share data while protecting people’s personal information.
In following posts we look a little bit more on decentralisation and medicine, especially manufacturing and research.
Next: Health Operator